 Explaining diffusion models with
Explaining diffusion models with Abstract
Text-to-image diffusion models have demonstrated an unparalleled ability to generate high-quality, diverse images from a textual prompt. However, the internal representations learned by these models remain an enigma. In this work, we present Conceptor, a novel method to interpret the internal representation of a textual concept by a diffusion model. This interpretation is obtained by decomposing the concept into a small set of human-interpretable textual elements. Applied over the state-of-the-art Stable Diffusion model, Conceptor reveals non-trivial structures in the representations of concepts. For example, we find surprising visual connections between concepts, that transcend their textual semantics. We additionally discover concepts that rely on mixtures of exemplars, biases, renowned artistic styles, or a simultaneous fusion of multiple meanings of the concept. Through a large battery of experiments, we demonstrate Conceptor's ability to provide meaningful, robust, and faithful decompositions for a wide variety of abstract, concrete, and complex textual concepts, while allowing to naturally connect each decomposition element to its corresponding visual impact on the generated images.
How does it work?
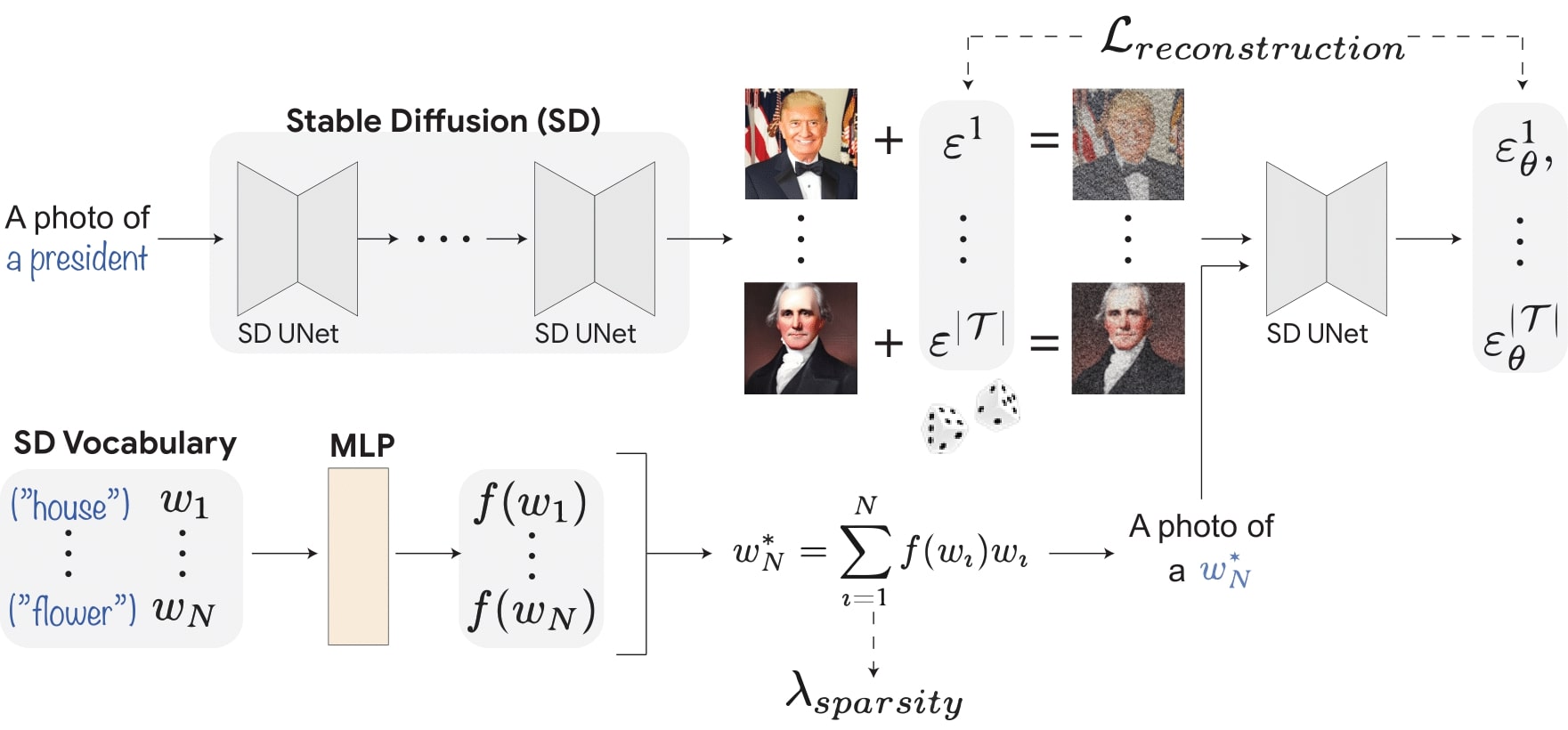
Given a text-to-image diffusion model (e.g., Stable Diffusion), and the concept of interest (e.g., a president), Conceptor learns to decompose the concept into a small set of human-interpretable tokens from the model's vocabulary. This is achieved by mimicking the training process of the model. (1) We extract a training set of 100 images from the model using the concept prompt. (2) A learned MLP network maps each word embedding wi from the model's vocabulary to its coefficient f(wi). (3) We calculate the learned pseudo-token w*N as a linear combination of the tokens in the vocabulary weighted by their learned coefficients. (4) We sample a random noise for each of the training images and noise the images accordingly. (5) Using the learned pseudo-token w*N, we apply the model's UNet to predict the added noise for each image. (6) We compute two loss functions. Lreconstruct encourages the token w*N to reconstruct the training images, and Lsparsity encourages the learned coefficients to be sparse. (7) In inference time, we only consider the top 50 tokens rated by their coefficients to reconstruct the concept images.
Concept Decomposition





Single Image Decomposition
Given a single image generated for the concept, Conceptor can decompose the image into its own set of corresponding tokens that cause the generation. We find that the model learns to rely on non-trivial, semantic connections between concepts. For example, a snake is decomposed to a hose and a gecko such that the shape of its body is borrowed from the hose, and its head and skin texture are borrowed from the gecko.

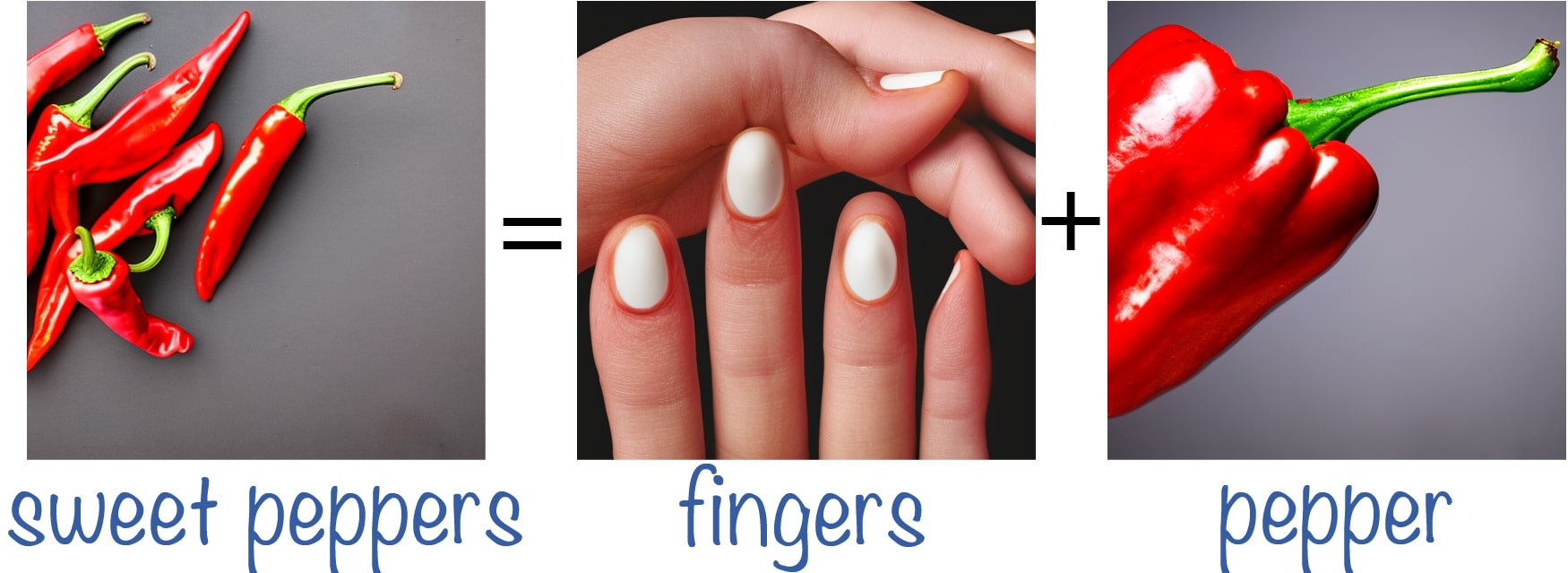


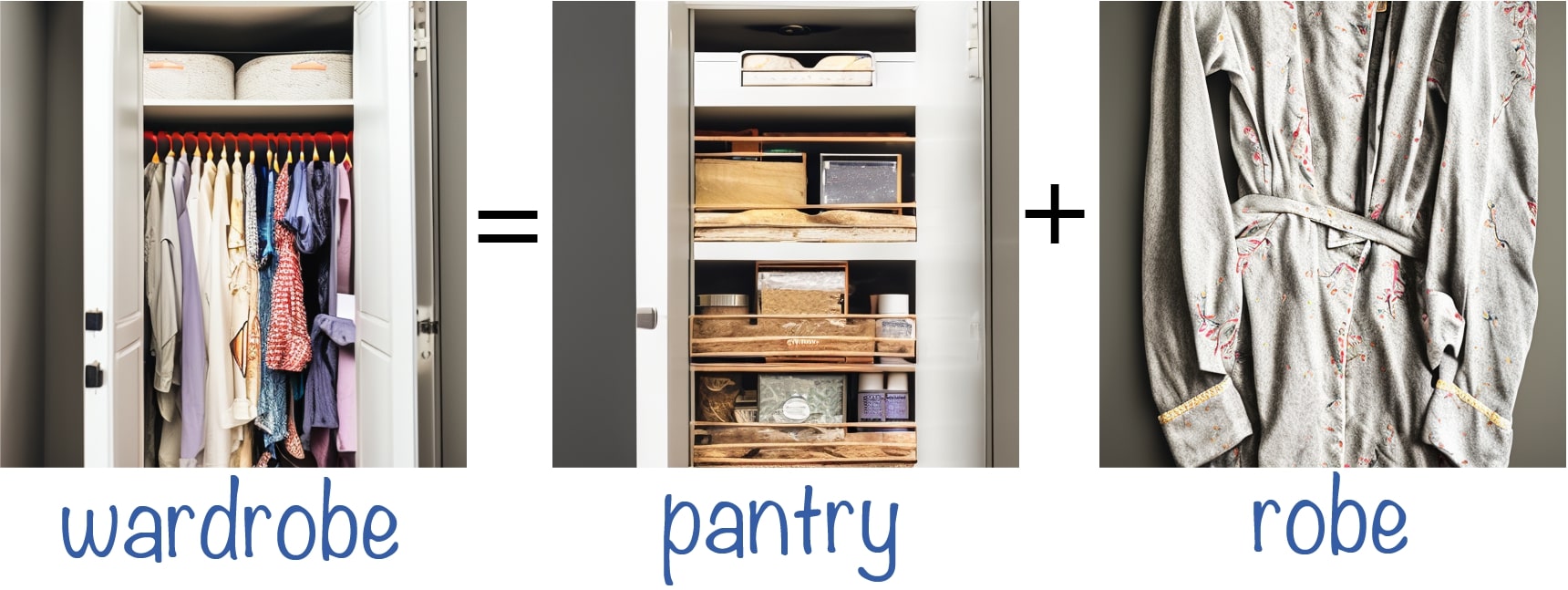
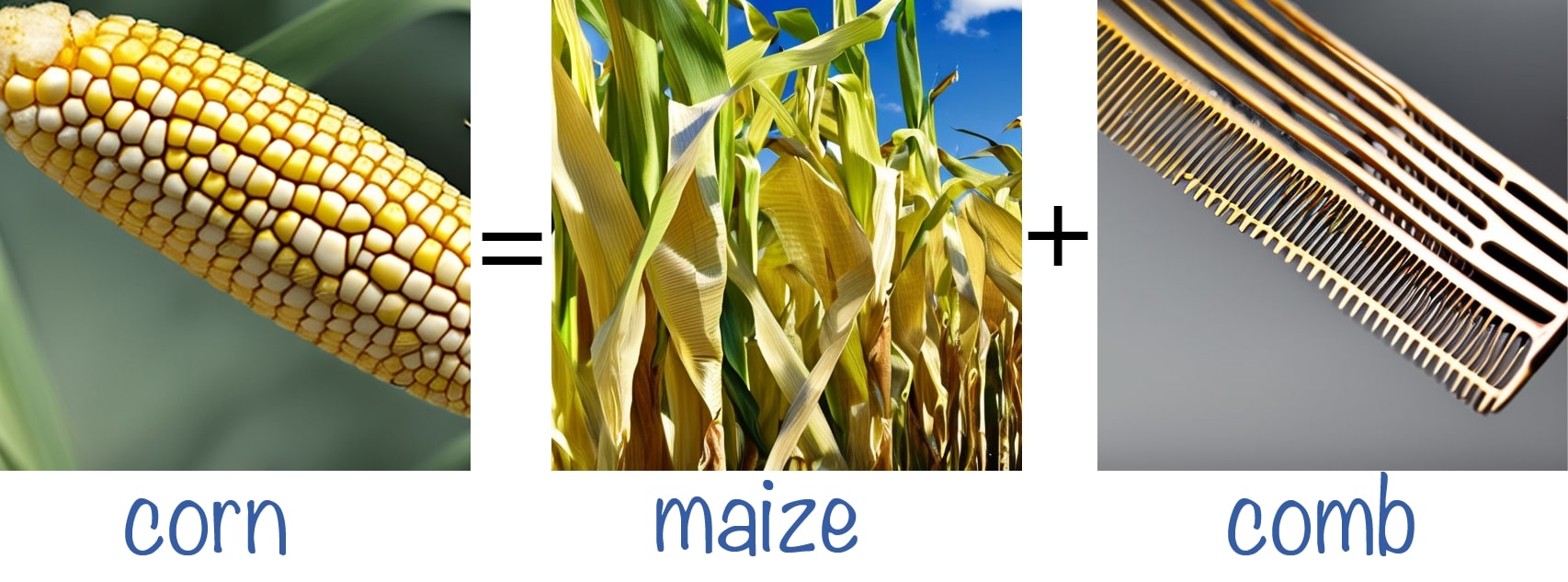


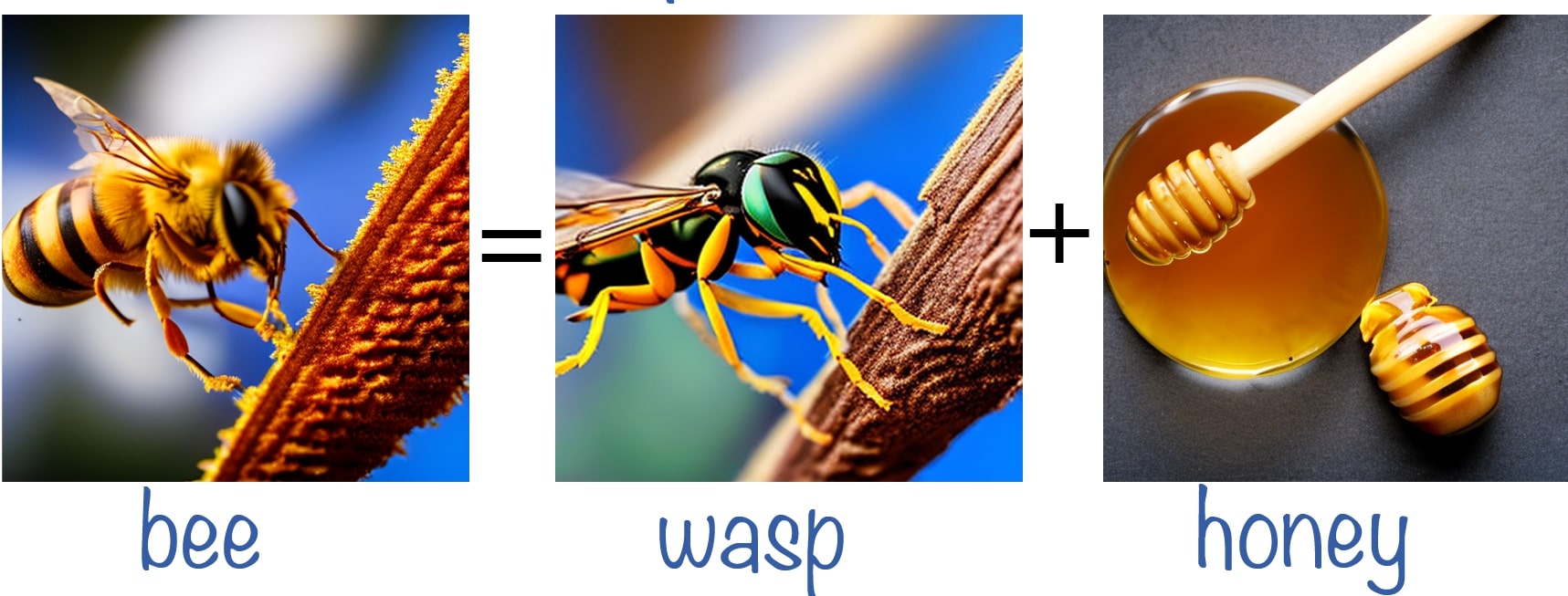
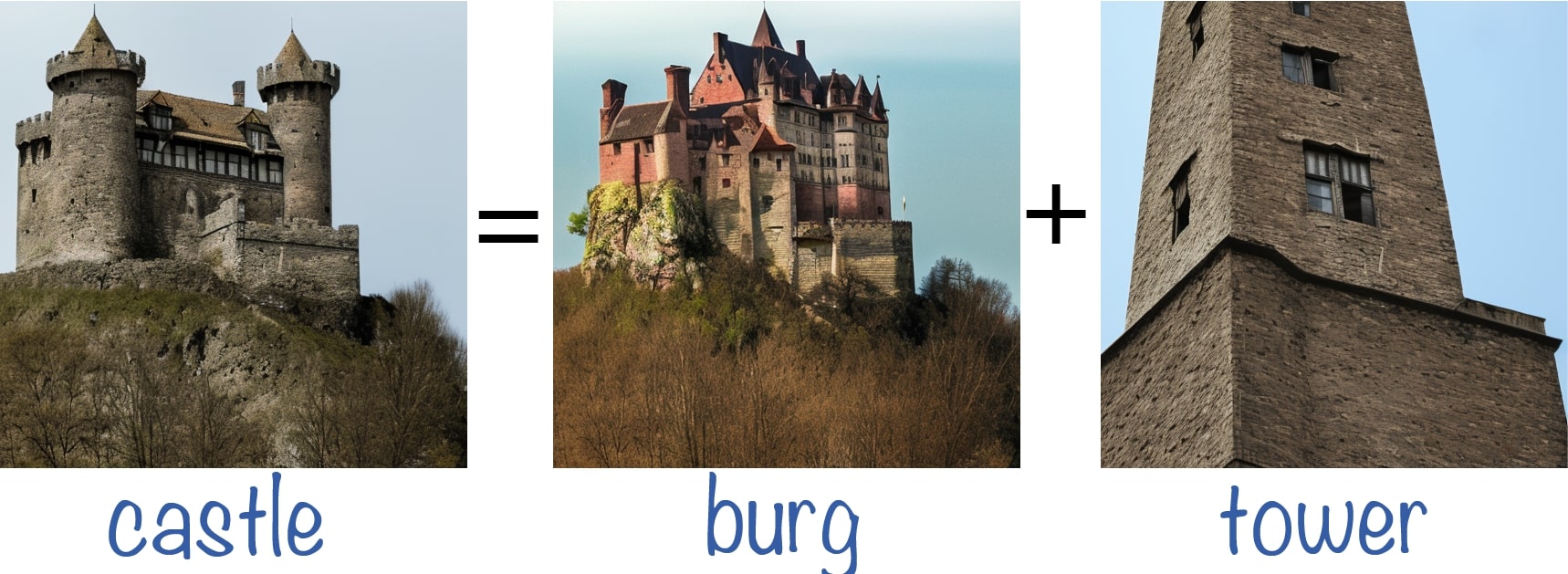
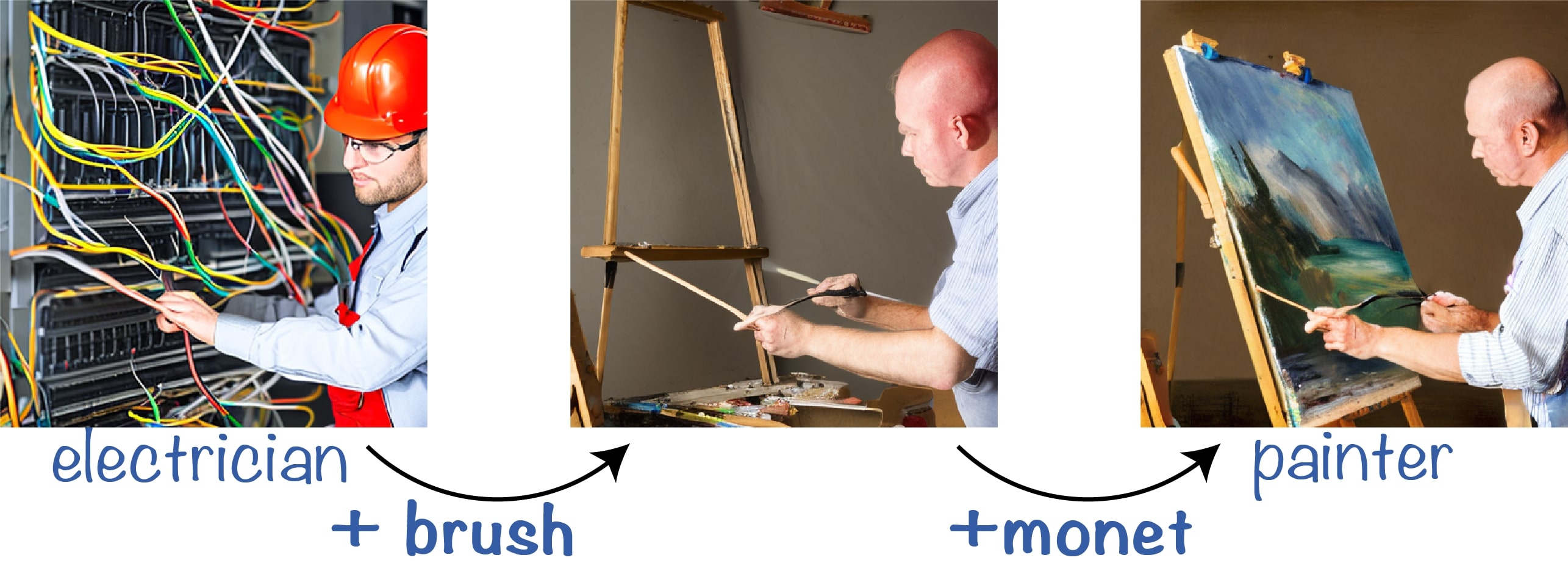
Double-Meaning Concepts
We conduct experiments using concepts with a dual meaning (e.g., a crane is a type of bird and also a construction tool) and manipulate the token that controls one of the meanings. We observe that even when only one object is generated, the image relies on both meanings of the concept (e.g., the crane is shaped like a bird's head). These examples demonstrate that the model entangles both meanings of the concept semantically to create the resulting image.






Concept Manipulation
Our method enables fine-grained concept manipulation by modifying the coefficient corresponding to a token of interest. For example, by manipulating the coefficient corresponding to the token abstract in the decomposition of the concept sculpture, we can make an input sculpture more or less abstract.






BibTeX
If you find this project useful for your research, please cite the following:
@article{chefer2023hidden,
title={The Hidden Language of Diffusion Models},
author={Chefer, Hila and Lang, Oran and Geva, Mor and Polosukhin, Volodymyr and Shocher, Assaf and Irani, Michal and Mosseri, Inbar and Wolf, Lior},
journal={arXiv preprint arXiv:2306.00966},
year={2023}
}